Through my Master Thesis, SANDA, I explored two interesting topics in the field of Chip Design and AI accelerators: Block-Floating Point (BFP) and Bit-Serial Architectures. These two concepts, while seemingly distinct, share a common goal of optimizing computational efficiency and resource utilization in hardware design.
As I often say, the simplest ideas are often the best. In this post, I will present and explain the concepts of BFP and Bit-Serial Architectures, highlighting their significance in modern computing.
This blog post is a good appetizer for the upcoming post about SANDA, a self-Adaptive Variable-Precision Accelerator for Efficient LLM Inference based on ANDA. SANDA is my master thesis project at KU Leuven in Chip Design and electronics master.
This post requires some basic knowledge of floating point representation, I highly recommend the tool float.exposed which is quite handy for visualizing. For a good understanding, I invite the reader to consult the great post by Fabien Sanglard on Floating Point Numbers. It helps to understand and visualize the FP value where the exponent is a window and the mantissa is an incremental slider between a superior and inferior value.
Block-Floating Point (BFP)
The idea of BFP is to represent a group of FP values with a single shared exponent. This method has the advantage of reducing the amount of memory required for storing and loading data, as well as simplifying arithmetic (especially thanks to dedicated ASIC units).
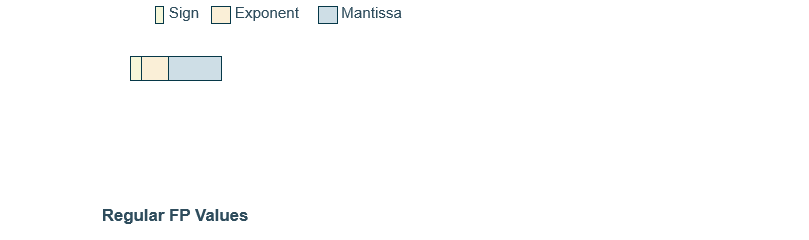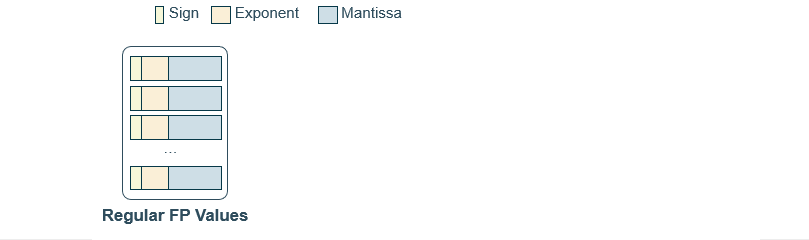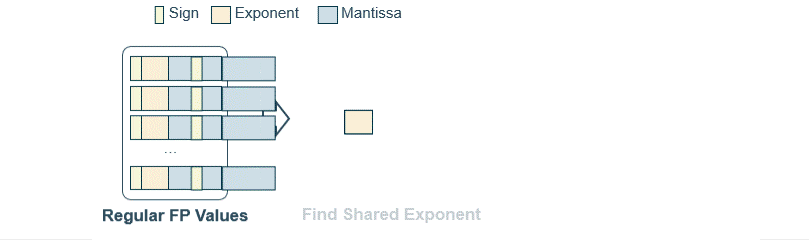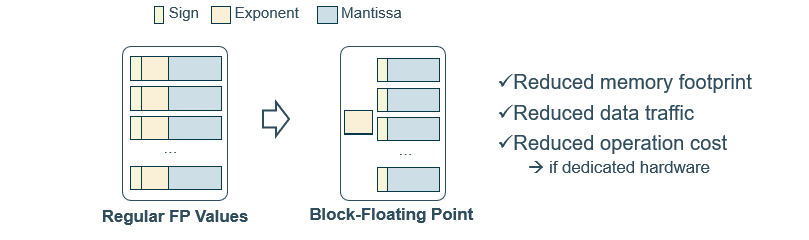
The first step is to group FP values together, a common approach is to group them in power of 2, for example 4, 8, 16, 32, etc. Then, we find the maximum exponent among the group of $2^n$ values.
After finding this maximum exponent, it is important to shift the mantissas of all values in the group, this is called alignment. The idea behind BFP is not to shift the mantissas - window - but rather to increase the width of that window. However, this comes at the cost of losing some precision in the mantissas, as we need some extra bits to represent which part of the window we are in.
Example
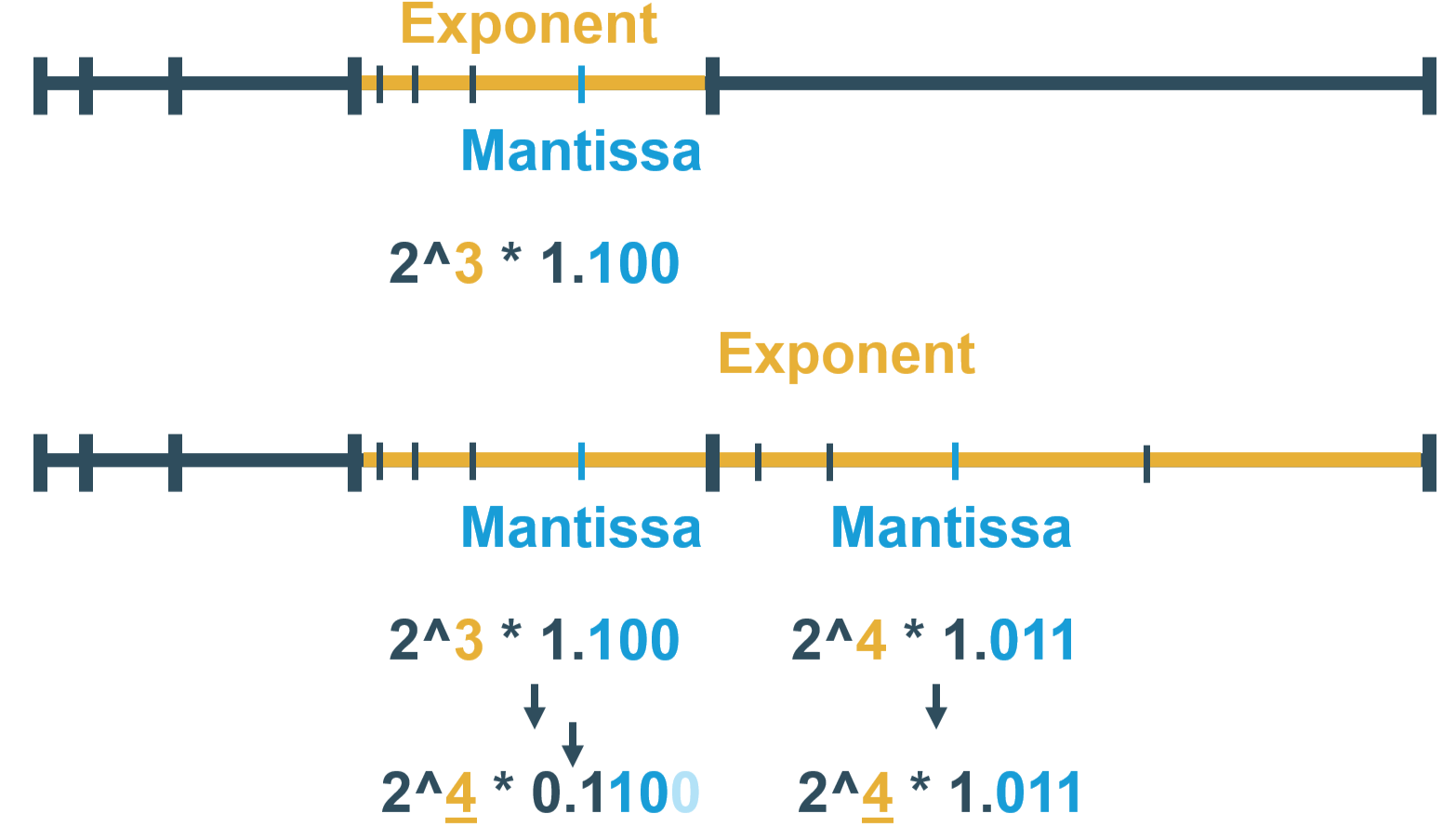
As seen in this simple example, we start from a number represented with \(2^3 \cdot 1.100_2\) where we have the exponent and the mantissa parts. Then when we have a group of 2 where we have also \(2^4 \cdot 1.011_2\), we need to align the mantissas. To do so, we calculate the delta of exponent between the highest and the exponent of the number we are considering. For our simple 2-element group, the maximum exponent is \(4\). The delta for \(2^3 \cdot 1.100_2\) is \(4-3=1\). We need 1 extra bit to align the mantissas. For this, we need to right shift the mantissa to represent in which part of the window we are in. Attention, we need to take into account the hidden bit of the mantissa, the \(1\) as seen in the example. So for \(2^3 \cdot 1.100_2\), it becomes \(2^4 \cdot 0.1100_2\) and for \(2^4 \cdot 1.011_2\), it stays the same as no delta is present. Finally, we must truncate the mantissa to keep the same bit-width throughout or the memory savings would be diminished. In this case, we truncate to 4 bits, so \(2^3 \cdot 0.1100_2\) becomes \(2^4 \cdot 0.110_2\) and \(2^4 \cdot 1.011_2\) becomes \(2^4 \cdot 1.011_2\).
Finally, we transform from FP to BFP representation, where now we have:
\[2^3 \cdot 1.100_2 \rightarrow 2^4 \cdot 0.110_2 \qquad 2^4 \cdot 1.011_2 \rightarrow 2^4 \cdot 1.011_2\]Summary
- Group FP values together (often in power of 2)
- Find the maximum exponent in the group
- Align the mantissa for each value
- Compute the delta between the current value and the maximum exponent
- Right shift the mantissa by the delta. Don’t forget the hidden bit!
- Truncate the mantissa to keep the same bit-width throughout the group
- You now have a BFP representation of your FP values group, gaining in efficiency and memory savings.
Bit-serial Processing
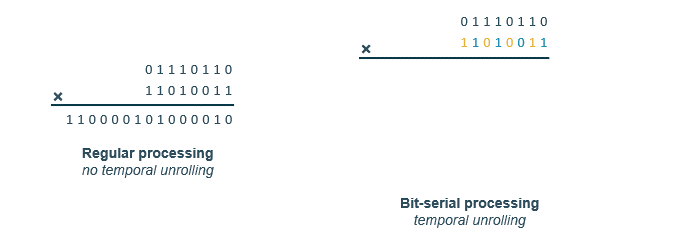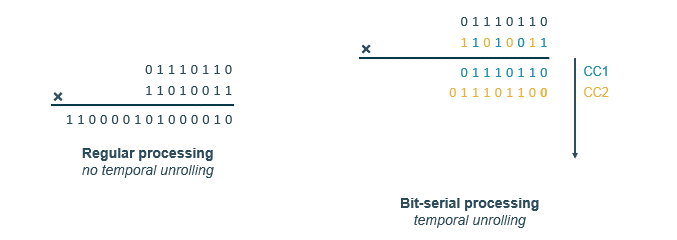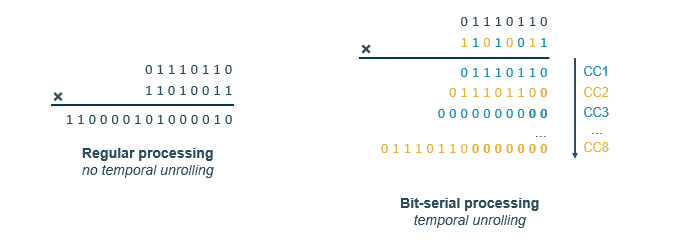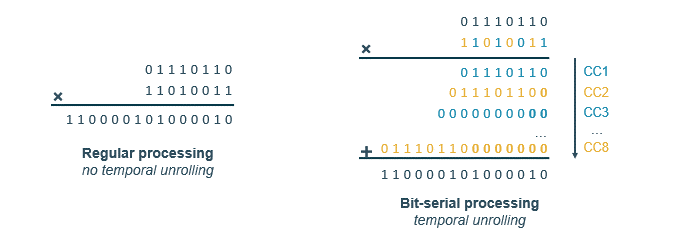
Besides regular arithmetic, where we process the entire number in one clock cycle, we can also process the value bit by bit, this is called bit-serial processing. The idea is to flip the problem by 90 degrees, and represent a trade-off in the Power Performance Area (PPA) of the chip.
It can be efficiently done as seen in the animation above. We go bit by bit, if the bit is 1, we add the value to the accumulator, if it is 0, we do nothing. At each new clock cycle, we must left-shift the result to keep the correct value from an arithmetic standpoint. At the end, we can simply sum up the results to get the final value. This method is particularly useful for low-precision arithmetic, as it allows for a more efficient use of hardware resources.
This method is also interesting for variable-length precision where, due to the trimming of BFP values, we can have a variable number of bits to process. Thus, leading to a variable number of clock cycles to process the value. This is particularly useful for LLM inference, where we can have a variable number of bits to process depending on the input data.